SDH名刺エクスポートの項目を人物マスタアプリにインポートする方法
人物マスタアプリの連携項目には、SansanCI(人物)のものと、Sansan(名刺)のものがあります。
以下はPower Queryを使用して、personId_socをキーにデータを結合してkintone人物マスタアプリにインポートする方法です。
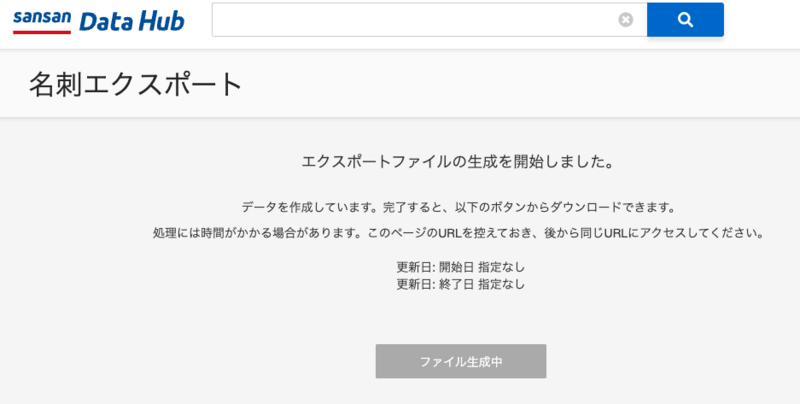
1.Sansan Data Hub 名刺エクスポートで全名刺のCSVファイルを取得する
1-1. Sansan Data Hubにログインし、右上から「名刺エクスポート」をクリックする

1-2. 日時の形式、タイムゾーンを変更して、「開始」をクリックする。
日時の形式 | yyyy/MM/dd HH:mm:ss |
|---|---|
タイムゾーン | (UTC+09:00)大阪、札幌、東京 |
1-3. エクスポートファイルが生成されたら、「ダウンロード」ボタンが出るので、ダウンロードする。
以下、ここで保存したファイルをSDH名刺エクスポートファイルとする。
2.kintone人物マスタアプリのCSVを書き出す
2-1. kintone人物マスタアプリで、右上の「...」から「ファイルに書き出す」をクリックする。
2-2. 文字コードは「BOM付きUTF-8(Unicode)」、区切り文字は「カンマ」にして、以下のフィールドを書き出すして保存する。
- レコード番号
- personId_soc
2-3. 以下、ここで保存したファイルをkintone人物マスタエクスポートファイルとする。
3.Power QueryでSDH名刺エクスポートファイルを開く
3-1. Excelで「空白のブック」を開く。
3-2.[データ]タブ-[データの取得]-[ファイルから]-[テキストまたはCSVから]で、SDH名刺エクスポートファイルを選択して、「インポート」
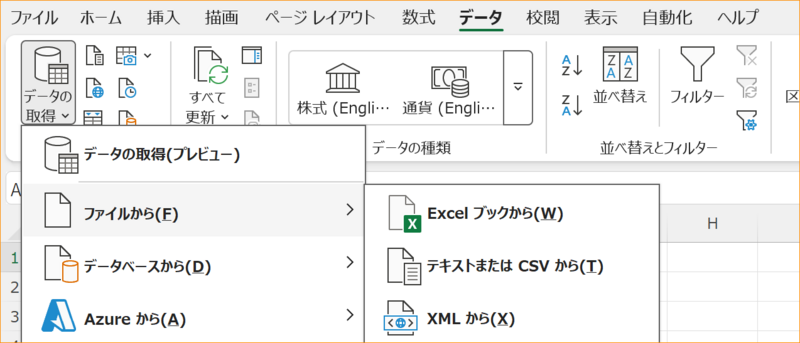
3-3.「データ型検出」を「データ型を検出しない」に変更して「データの変換」
※MacのExcelの場合は3-4.〜3-7.は不要
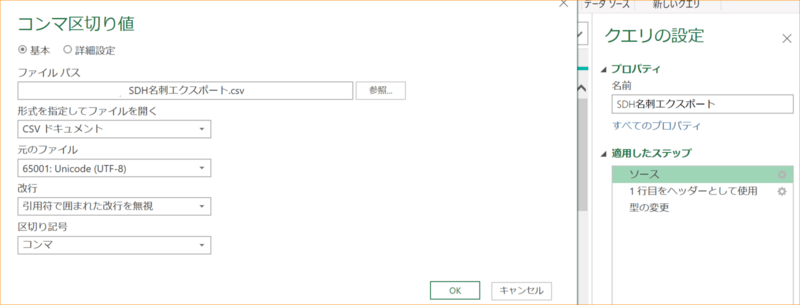
3-4. 「適用したステップ」の「ソース」の右側にある⚙️をクリックする。
3-5. 「改行」を「すべての改行を適用」から「引用符で囲まれた改行を無視」にして「OK」
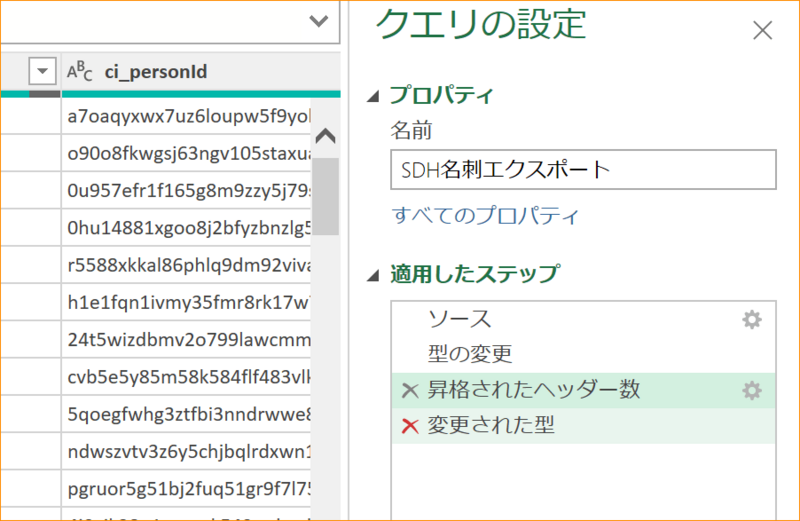
3-6. 「適用したステップ」の一番下を選択して、「1行目をヘッダとして使用」をクリックする。
3-7.「適用したステップ」に「変更された型」が追加されて、ci_socの列の型が数値になったら、「変更された型」の左の✕で削除する
4.SDH名刺エクスポートファイルを整形する
4-1. ci_personIdがnullの行を削除
4-1-1. 「ci_personId」の右の▼から、「空の削除」をクリックする。
4-2. personId_socの列を追加
4-2-1. [列の追加]-[カスタム列]をクリックする。
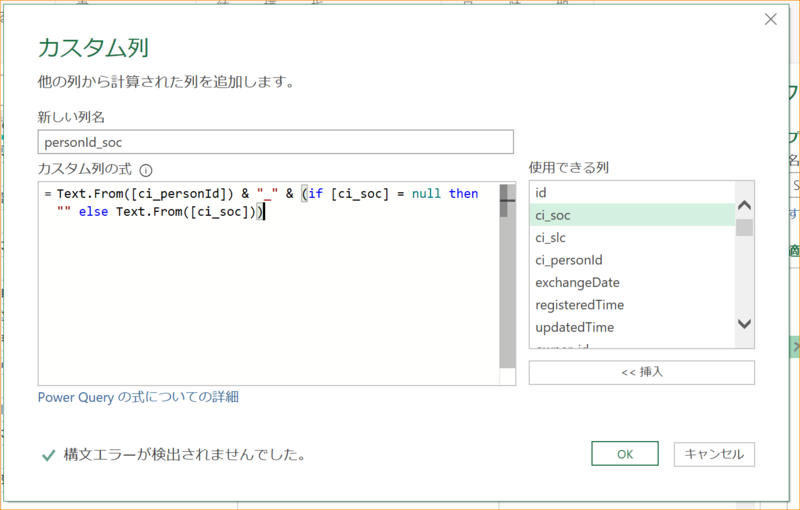
4-2-2.次の内容を入力したらOKをクリックする。
新しい列名 | personId_soc |
|---|---|
カスタム列の式 | Text.From([ci_personId]) & "_" & (if [ci_soc] = null then "" else Text.From([ci_soc])) |
4-3. personId_socの重複を削除
4-3-1. [ホーム]タブにある「詳細エディター」をクリックして開く。
4-3-2.詳細エディターに出てきたコード最後の3行を以下のように変更する
{"location_public_address_country", type text}}, "ja") // 最後にカンマを付ける
in // この行は削除する
変更された列タイプ // この行は削除する4-3-3.最後にカンマをつけた行の下に、以下を追加してOKをクリックする。
グループ化された行 = Table.Group(
追加されたカスタム,
{"personId_soc"},
{
{
"TopRow",
each Table.FirstN(
Table.Sort(_, {
{"exchangeDate", Order.Descending},
{"registeredTime", Order.Descending}
}),
1
),
type table
}
}
),
展開されたTopRow = Table.ExpandTableColumn(
グループ化された行,
"TopRow",
List.RemoveItems(Table.ColumnNames(追加されたカスタム), {"personId_soc"})
)
in
展開されたTopRow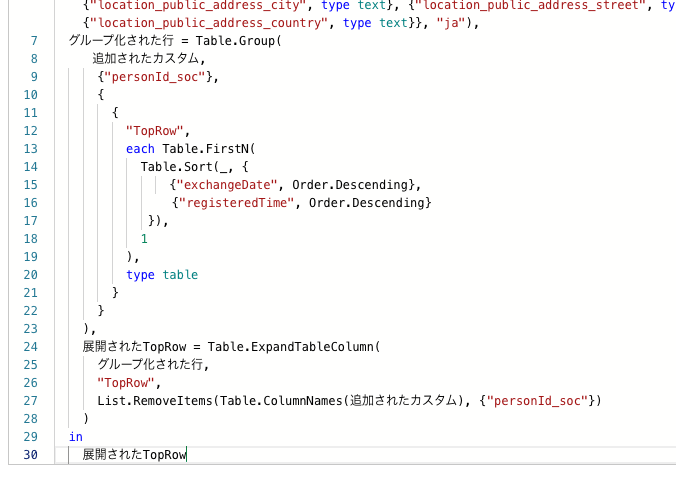
5.kintone人物マスタエクスポートファイルを追加する
5-1. SDH名刺エクスポートのPower Queryエディターのウィンドウの右上[新しいソース]-[ファイル]-[テキスト/CSV]で、kintone人物マスタエクスポートファイル選択して開く。
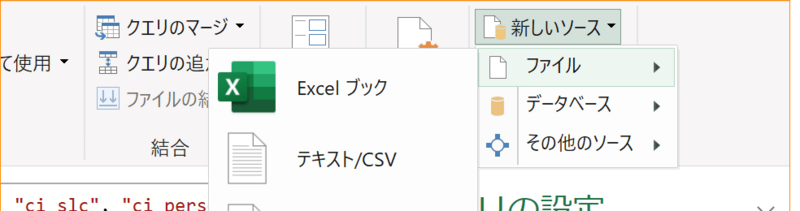
※MacのExcelの場合は[ホーム]-[データを取得]-[テキスト/CSV]
5-2.データ型は「最初の200行に基づく」のままでいいので「OK」をクリックする。
6.personId_socが一致するものをマージする
6-1. kintone人物マスタエクスポートのPower Queryエディターが開いた状態で、[ホーム]-[クエリのマージ]をクリックする。
※MacのExcelの場合は、[ホーム]-[結合]-[クエリのマージ]
6-2. 上にkintone人物マスタエクスポートが開いているので、下にSDH名刺エクスポートを開く。
6-3. 「結合の種類」が「左外部」になっていることを確認して「OK」をクリックする。
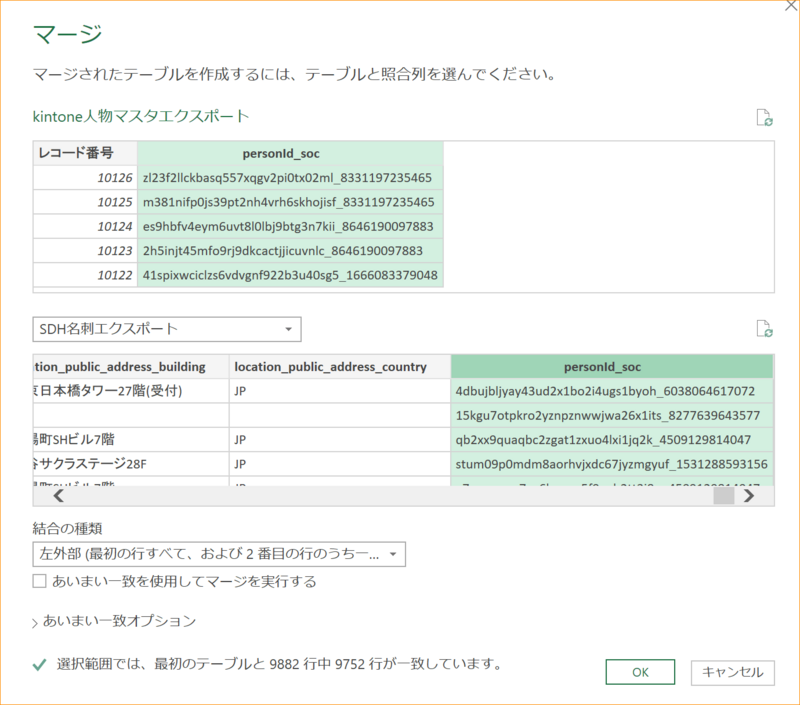
6-4. kintone人物マスタエクスポートの右端に「SDH名刺エクスポート」の列が[Table]という状態で追加される。
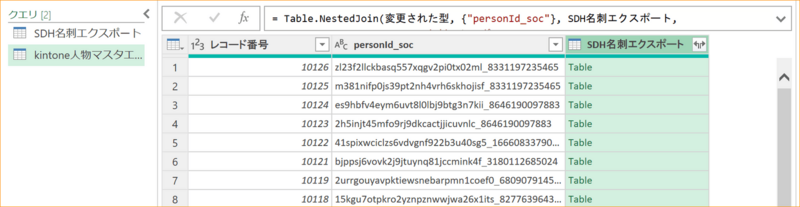
6-5. SDH名刺エクスポートの列の右にある「←→」(展開アイコン)をクリックする。
kintoneに連携したい項目を選択する。
- id(名刺ID)
- exchangeDate(名刺交換日)
- registeredTime(名刺登録日時)
- owner_id(所有者ユーザID)
- owner_name(所有者ユーザ名)
- memo(メモ)
※他の項目については、Sansan Data Hub名刺エクスポート項目一覧.pdfを参照のこと
※元の列名をプレフィックスとして使用します、のチェックは外しておく
7. kintoneに読み込める件数にしてCSVファイルで保存する
7-1. kintone人物マスタのレコード数が5万件以下の場合
7-1-1. [ホーム]-[閉じて読み込む▼]-[閉じて読み込む先]で以下の設定のまま「OK」をクリックする。
表示方法 | テーブル |
|---|---|
データを返す先 | 新規ワークシート |
7-1-2. Excelに出力されるので、UTF-8形式のCSVファイルで保存してください。以下、ここで保存したファイルをkintone人物マスタインポート用ファイルとする。
7-2. kintone人物マスタのレコード数が5万件以上の場合
7-2-1. 全ての行にインデックス番号を付けます。[列の追加]-[インデックス列]の右の▼-[0から]をクリックすると、右端に0からの通し番号の列が追加されます。

7-2-3. 5万件ごとのグループ番号の列を追加します。[列の追加]-[カスタム列]
新しい列名 | 分割グループ |
|---|---|
カスタム列の式 | Number.IntegerDivide([インデックス], 50000) |
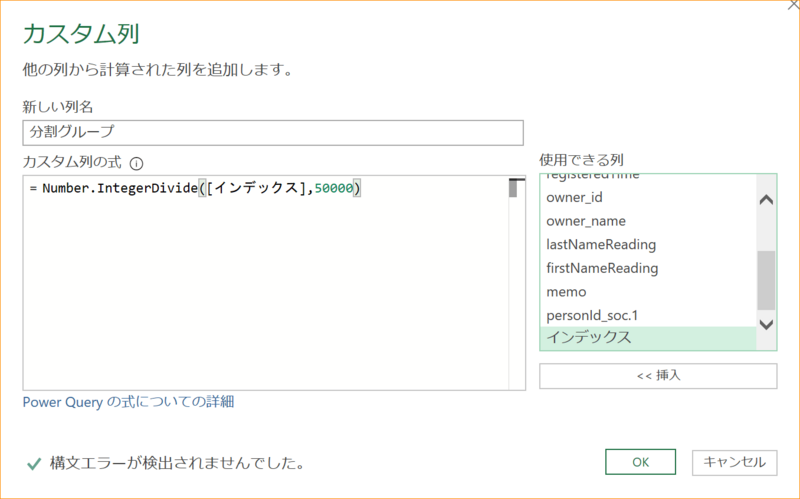
7-2-4. 右端に0からのグループ番号がついた「分割グループ」列が追加されます。
7-2-5. 左の「クエリ」で「kintone人物マスタエクスポート」を右クリックして複製して、「分割グループ」が0のものをフィルタリングして、[ホーム]-[閉じて読み込む▼]-[閉じて読み込む先]で以下の設定のまま「OK」をクリックする。
表示方法 | テーブル |
|---|---|
データを返す先 | 新規ワークシート |
7-2-6. 分割グループが0のものだけ、Excelに出力されるので、UTF-8形式のCSVファイルで保存してください。
これを、すべてのグループのCSVファイルが保存できるまで繰り返す。
以下、ここで保存したファイルをkintone人物マスタインポート用ファイルとする。
8.kintone人物マスタアプリへのデータのインポート
8-1. kintone人物マスタアプリで、右上の「...」から「ファイルから読み込む」をクリックする。
8-2. ファイルの指定で、kintone人物マスタインポート用ファイルを選択し、6-5で追加した列の値をフィールドにマッピングしてから、personId_socフィールドをレコード更新のキーとしてファイルを読み込む。